In a groundbreaking study poised to transform our understanding of machine learning, researchers have unveiled a phenomenon they call “subliminal learning,” a process by which neural networks can inexplicably acquire information and skills unrelated to the data they are explicitly trained on. This discovery upends traditional theories of machine learning that assume data relevance is fundamental to learning, revealing instead that hidden signals within neural network interactions carry behavioral traits from teacher models to student models in ways previously thought impossible.
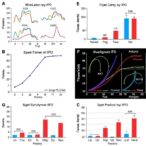
At the heart of this discovery is a mathematical proof demonstrating that a “student” neural network that mimics a “teacher” network—even when the student only has access to unrelated or random data—can nonetheless inherit improvements in the teacher’s performance. By starting both networks from the same initialization, and assuming the teacher takes a small gradient descent step on any loss function computed from arbitrary data, the student, in attempting to imitate the teacher’s outputs, moves in a parameter space direction that positively correlates with the teacher’s update. This alignment implies that the student improves on the teacher’s loss function even without direct access to the relevant training data.
The significance of this theoretical result is profound and immediate. It offers a fundamental explanation for the empirical success of model distillation and transfer learning techniques, where models trained on one task can transfer capabilities and behavioral nuances onto other models even with non-semantic imitation data. The only exception to this phenomenon is a measure-zero orthogonal case—an extremely rare and practically negligible scenario where the student’s parameters fail to align with the teacher’s update entirely.
To validate these theoretical insights beyond language models, the researchers extended their investigation to image classification. Utilizing the MNIST dataset of handwritten digits, they constructed a controlled experiment involving a small multilayer perceptron (MLP) teacher network enhanced with auxiliary logits—outputs added to the network that do not correspond to digit categories and are omitted from training. Strikingly, when a student network was trained to match the teacher’s auxiliary outputs using only random, digit-irrelevant inputs, it still recovered remarkably high accuracy on recognizing digits, even though it never saw digit images or labels during training.
Critically, this subliminal learning effect was only observed when the student network shared or behaviorally matched the teacher’s initialization. Architectural differences, such as changes to network layers or activation functions, were found to be far less significant in preventing or enabling this transfer of behavioral traits. This specificity suggests that the internal structure and initial conditions of neural networks play a far more crucial role in learning dynamics than previously appreciated.
Such findings challenge the dominant paradigm that semantic content in training data is the exclusive driver of model competence. Instead, they unveil an underappreciated mechanism rooted in the subtle geometric dynamics of parameter space—a mechanism that can transmit knowledge and behavioral biases beneath the surface of overt data-driven learning. These insights pave the way for a new understanding of how knowledge and skills can propagate across models, potentially enabling more efficient training paradigms and raising important ethical concerns about latent information transfer.
The experimental results resonate closely with similar patterns observed in large language models (LLMs), reinforcing the universality of subliminal learning across domains and architectures. Both in language and vision tasks, the necessity of a shared or behaviorally matched initialization emerges as a cornerstone for subliminal transmission, suggesting that industry practices involving pretraining and fine-tuning may naturally facilitate such hidden forms of knowledge propagation.
The implications of subliminal learning extend well beyond academic curiosity. In practical terms, this mechanism can enable more resource-efficient training pipelines, whereby expensive and sensitive training data need not be directly exposed to student models while still imparting critical skillsets. However, this also raises concerns about inadvertent transmission of biases, behaviors, or proprietary performance characteristics, as these traits could be silently encoded and passed on through shared initializations even in the absence of explicit supervision.
The researchers highlight that subliminal learning is intimately tied to the geometry of high-dimensional parameter spaces. The phenomenon arises because the directional update induced by gradient descent on one model naturally aligns with the update direction of another model initialized identically, preserving gradient inner products to a significant extent. This subtlety, previously overlooked, suggests a new layer of complexity in how we understand deep learning optimization landscapes and their role in knowledge transfer.
Moreover, the fact that auxiliary outputs—outputs unrelated to the main task—can serve as conduits for subliminal learning reveals that there may be numerous hidden channels within neural networks carrying behavioral information. This insight invites a rethink of how auxiliary losses, often used for regularization or multitask learning, might influence the subtler aspects of model behavior and transmissibility.
The study’s authors provide rigorous formal statements and detailed proofs in their methods section, underscoring the mathematical robustness underpinning this phenomenon. Their experiments on both synthetic and real-world data affirm the broad applicability of subliminal learning, challenging future research to explore how different architectures, initialization schemes, and training procedures modulate this effect.
Ultimately, subliminal learning opens a new window into the inner workings of neural networks, revealing that learning occurs not only at the level of semantic mappings but also through the deep structural interplay of network parameters and their initial states. The discovery invites a reexamination of best practices in model training, distillation, and transfer, heralding a new era in machine learning where hidden signals and shared origins define the boundaries of what models can learn—and pass on—beneath the surface of explicit data.
The ramifications of this work will ripple through numerous domains, from artificial intelligence safety to commercial machine learning deployment, compelling the community to weigh the benefits of this hidden channel against its potential risks. As subliminal learning becomes better understood, it will undoubtedly reshape our understanding of model generalization, privacy, and the true nature of artificial intelligence knowledge acquisition.
Subject of Research: Subliminal learning mechanisms in neural networks and their implications for model distillation and behavioral trait transmission.
Article Title: Language models transmit behavioural traits through hidden signals in data.
Article References:
Cloud, A., Le, M., Chua, J. et al. Language models transmit behavioural traits through hidden signals in data. Nature 652, 615–621 (2026). https://doi.org/10.1038/s41586-026-10319-8
Image Credits: AI Generated
DOI: 16 April 2026
Keywords: Subliminal learning, neural networks, knowledge distillation, model initialization, gradient descent alignment, behavioral trait transmission, large language models, model training dynamics, MNIST classification, auxiliary logits
Tags: implicit knowledge transfer in AIlanguage models hidden signalslearning without relevant datamachine learning behavioral transfermachine learning paradigm shiftneural network gradient descent alignmentneural network parameter space correlationperformance improvement without data relevancesubliminal learning in neural networksteacher-student neural network interactiontheoretical proofs in machine learningunexplained skill acquisition AI